使用自定义数据进行Qlib回测
天之道,损有余而补不足;人之道,损不足而奉有余
Qlib是微软出品的开源量化投资平台,包含数据处理、模型构建、交易策略、决策执行、数据分析等一系列功能模块。在对股票市场数据的预测和分析中,我们常常需要对一些模型在历史数据上进行回测。而Qlib提供了这样一个回测框架,能够在自己收集到的数据上进行测试,并输出相应的图形化结果,下面就来试试吧!
数据准备
这里以沪深300指数数据为例子,因为Qlib自带的数据时间只到2020年,所以需要我们自己去下载最新的数据。这里我选择baostock来下载数据,页面中也给出了对应的python代码。在Qlib中指数数据被称为benchmark,与股票市场数据区分开来,具体可以看下面的代码注释:
CSI300_BENCH = "SH000300"
# Benchmark is for calculating the excess return of your strategy.
# Its data format will be like **ONE normal instrument**.
# For example, you can query its data with the code below
# `D.features(["SH000300"], ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')`
# It is different from the argument `market`, which indicates a universe of stocks (e.g. **A SET** of stocks like csi300)
# For example, you can query all data from a stock market with the code below.
# ` D.features(D.instruments(market='csi300'), ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')`
首先可以根据时间测试一下是否有对应的数据,为了方便导入,首先将baostock中的沪深300数据下载下来存储为csv文件,具体代码如下:
from pprint import pprint
import baostock as bs
import qlib
from qlib.constant import REG_CN
import pandas as pd
from qlib.backtest import backtest, executor
from qlib.contrib.evaluate import risk_analysis
from qlib.contrib.strategy import TopkDropoutStrategy
# load lib for benchmark
from qlib.backtest.report import PortfolioMetrics
from qlib.utils.time import Freq
from qlib.utils import flatten_dict
from qlib.contrib.report import analysis_position
# init qlib
qlib.init(provider_uri=r'data/qlib/cn_data', region=REG_CN)
def test_qlib_benchmark(benchmark, start_time, end_time):
benchmark_config = {
"benchmark": benchmark,
"start_time": start_time,
"end_time": end_time,
}
portfolio_metrics = PortfolioMetrics('day', benchmark_config)
print(portfolio_metrics.bench)
def add_qlib_benchmark(index_code, start_time, end_time):
'''
Description: 获取指数(综合指数、规模指数、一级行业指数、二级行业指数、策略指数、成长指数、价值指数、主题指数)K线数据并添加到qlib数据以进行回测
Parameters:
index_code:指数代码,综合指数,例如:sh.000001 上证指数,sz.399106 深证综指 等;
规模指数,例如:sh.000016 上证50,sh.000300 沪深300,sh.000905 中证500,sz.399001 深证成指等;
一级行业指数,例如:sh.000037 上证医药,sz.399433 国证交运 等;
二级行业指数,例如:sh.000952 300地产,sz.399951 300银行 等;
策略指数,例如:sh.000050 50等权,sh.000982 500等权 等;
成长指数,例如:sz.399376 小盘成长 等;
价值指数,例如:sh.000029 180价值 等;
主题指数,例如:sh.000015 红利指数,sh.000063 上证周期 等;
start_time: 开始时间
end_time: 结束时间,要比实际时间+1天
'''
# 登陆系统
lg = bs.login()
# 显示登陆返回信息
print('login respond error_code:'+lg.error_code)
print('login respond error_msg:'+lg.error_msg)
rs = bs.query_history_k_data_plus(index_code,
"date,code,open,high,low,close,preclose,volume,amount,pctChg",
start_date=start_time, end_date=end_time, frequency="d")
print('query_history_k_data_plus respond error_code:'+rs.error_code)
print('query_history_k_data_plus respond error_msg:'+rs.error_msg)
# 打印结果集
data_list = []
while (rs.error_code == '0') & rs.next():
# 获取一条记录,将记录合并在一起
data_list.append(rs.get_row_data())
result = pd.DataFrame(data_list, columns=rs.fields)
# 结果集输出到csv文件
result.rename(columns={'code':'symbol'},inplace=True)
result.loc[:, 'symbol'] = "SH000300"
result.to_csv(r"data/csv/SH000300.csv", index=False)
print(result)
# 登出系统
bs.logout()
# init qlib
qlib.init(provider_uri=r'data/qlib/cn_data', region=REG_CN)
try:
test_qlib_benchmark('SH000300', "2023-03-06", "2023-08-24")
except ValueError:
print('Please add SH000300 csv data with "add_custom_benchmark.sh"!')
add_qlib_benchmark('sh.000300', "2023-03-06", "2023-08-25")
exit(0)
在回测时,沪深300的成分股市场数据也需要导入到Qlib中来计算超额收益,同样地我将它们存成了csv格式,示例代码如下:
def transform_qlib_format(df):
sym = np.unique(df['symbol'])
#np.savetxt(r'data/csi300.txt',sym,fmt='%s')
for i,isym in tqdm(enumerate(sym)):
ohlcv_filter = df[df['symbol'] == isym]
ohlcv_filter.to_csv(r'data/csv/'+isym+'.csv', index=False)
注意要将股票代码的列名命名为symbol,其它列名一般就是包含开盘价(open)、收盘价(close)、最高价(high)、最低价(low)、交易量(volume)。然后就是根据官方提供的工具,将数据导入Qlib目录,具体bash脚本如下:
#!/usr/bin/bash
FILE="./dump_bin.py"
if [ -f "$FILE" ]; then
echo "$FILE exists."
else
echo "$FILE does not exist! try download from github using curl"
curl -O https://raw.githubusercontent.com/microsoft/qlib/refs/heads/main/scripts/dump_bin.py
fi
FILE="./data/qlib/cn_data"
if [ -f "$FILE" ]; then
echo "$FILE exists."
else
echo "$FILE does not exist! Creating folder..."
mkdir -p data/qlib/cn_data
fi
python dump_bin.py dump_all --csv_path data/csv --qlib_dir data/qlib/cn_data/ --include_fields open,close,high,low,volume --symbol_field_name symbol --date_field_name date
然后再次运行一下上面的test_qlib_benchmark函数,应该能够正常读到数据。
模型回测
这里模型回测需要用到自己的模型预测的输出,同样也存储成csv文件。列名分别是:datetime,instrument,score,label。然后就可以配合官方的回测代码进行测试,我修改后的代码如下:
#def backtest_custom_benchmark(BENCH: str = "SH000300", start_date: str = "2023-03-06", end_date: str = "2023-08-24", pred_score: pd.Series=pd.Series([],dtype=int)):
"""
Backtest with custom benchmark
"""
# Benchmark is for calculating the excess return of your strategy.
# Its data format will be like **ONE normal instrument**.
# For example, you can query its data with the code below
# `D.features(["SH000300"], ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')`
# It is different from the argument `market`, which indicates a universe of stocks (e.g. **A SET** of stocks like csi300)
# For example, you can query all data from a stock market with the code below.
# ` D.features(D.instruments(market='csi300'), ["$close"], start_time='2010-01-01', end_time='2017-12-31', freq='day')`
pred_score = pd.read_csv(r'data/output/test.csv')
pred_score["datetime"] = pd.to_datetime(pred_score["datetime"])
pred_label = pred_score.set_index(["instrument", "datetime"])
pred_score = pred_score.set_index(["datetime", "instrument"])["score"]
STRATEGY_CONFIG = {
"topk": 50,
"n_drop": 5,
# pred_score, pd.Series
"signal": pred_score,
}
EXECUTOR_CONFIG = {
"time_per_step": "day",
"generate_portfolio_metrics": True,
}
backtest_config = {
"start_time": "2023-03-06",
"end_time": "2023-08-24",
"account": 100000000,
"benchmark": "SH000300",
"exchange_kwargs": {
"freq": "day",
"limit_threshold": 0.095,
"deal_price": "close",
"open_cost": 0.0005,
"close_cost": 0.0015,
"min_cost": 5,
},
}
# strategy object
strategy_obj = TopkDropoutStrategy(**STRATEGY_CONFIG)
# executor object
executor_obj = executor.SimulatorExecutor(**EXECUTOR_CONFIG)
# backtest
portfolio_metric_dict, indicator_dict = backtest(executor=executor_obj, strategy=strategy_obj, **backtest_config)
analysis_freq = "{0}{1}".format(*Freq.parse("day"))
# backtest info
report_normal, positions_normal = portfolio_metric_dict.get(analysis_freq)
# analysis
analysis = dict()
analysis["excess_return_without_cost"] = risk_analysis(
report_normal["return"] - report_normal["bench"], freq=analysis_freq
)
analysis["excess_return_with_cost"] = risk_analysis(
report_normal["return"] - report_normal["bench"] - report_normal["cost"], freq=analysis_freq
)
analysis_df = pd.concat(analysis) # type: pd.DataFrame
# log metrics
analysis_dict = flatten_dict(analysis_df["risk"].unstack().T.to_dict())
# print out results
pprint(f"The following are analysis results of benchmark return({analysis_freq}).")
pprint(risk_analysis(report_normal["bench"], freq=analysis_freq))
pprint(f"The following are analysis results of the excess return without cost({analysis_freq}).")
pprint(analysis["excess_return_without_cost"])
pprint(f"The following are analysis results of the excess return with cost({analysis_freq}).")
pprint(analysis["excess_return_with_cost"])
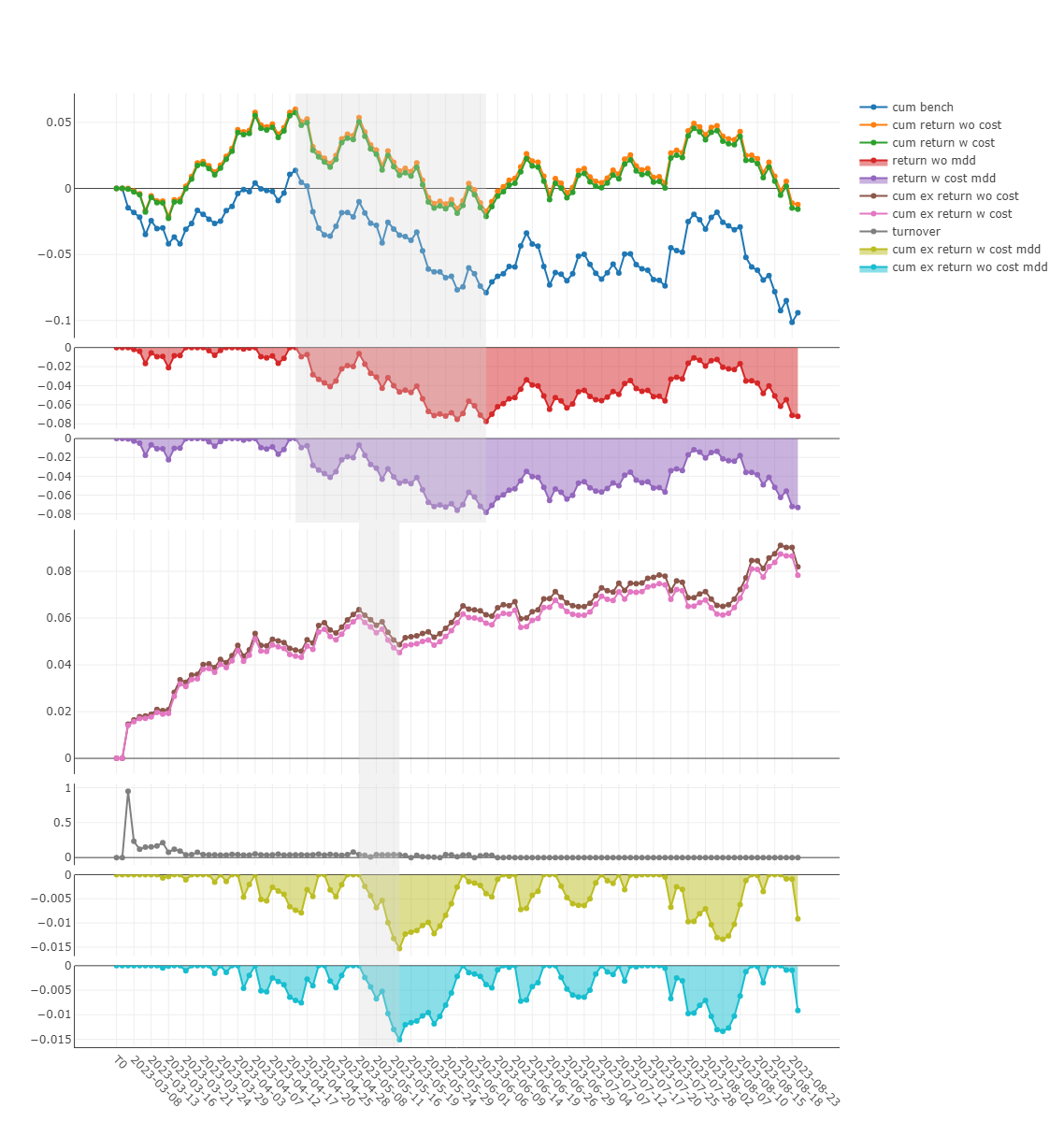
最后还可以拿工具画出回测结果分析图,如下:
analysis_position.report_graph(report_normal)
analysis_position.score_ic_graph(pred_label)
![]()
| 微信(WeChat Pay) | 支付宝(AliPay) |

|

|
| 比特币(Bitcoin) | 以太坊(Ethereum) |

|

|
| 以太坊(Base) | 索拉纳(Solana) |

|

|