Neural Network Notes
Neural networks, a beautiful biologically-inspired programming paradigm which enables a computer to learn from observational data
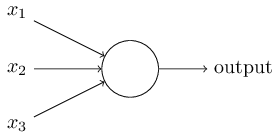
Perceptron
A perceptron takes several binary inputs, x1,x2,…, and produces a single binary output:
SGD
To quantify how well we’re achieving this goal we define a cost function: \(C(w,b)=\frac1{2n}\sum_x{\left|y(x)-a \right|^2}\) Here, w denotes the collection of all weights in the network, b all the biases, n is the total number of training inputs, a is the vector of outputs from the network when x is input, and the sum is over all training inputs, x. Of course, the output a depends on x, w and b, but to keep the notation simple I haven’t explicitly indicated this dependence. The notation ‖v‖ just denotes the usual length function for a vector v. We’ll call C the quadratic cost function; it’s also sometimes known as the mean squared error or just MSE.
Back Propagation
\[\delta^l_j=\frac{\partial C}{\partial a^l_j}\sigma^\prime(z^l_j)\] \[\delta^l=((\omega^{l+1})^T\delta^{l+1})*\sigma^\prime(z^l)\] \[\frac{\partial C}{\partial b^l_j}=\delta^l_j\] \[\frac{\partial C}{\partial \omega^l_{jk}}=a^{l-1}_k\delta^l_j\]Initialnization
Then we shall initialize those weights as Gaussian random variables with mean 0 and standard deviation $\frac1{\sqrt{n_{in}}}$
Cross-entropy Cost Function
\[C=-\frac1n\sum_x[y\ln a+(1-y)\ln(1-a)]\]where n is the total number of items of training data, the sum is over all training inputs , x, and y is the corresponding desired output.
Softmax
\[a^L_j=\frac{e^{z^L_j}}{\sum_ke^{z^L_k}}\]Regularization
\[\frac{\lambda}{2n}\sum_ww^2\]Dropout
Dropout is a radically different technique for regularization.
Hyperparameter
learining rate $\eta$ regularization parameter $\lambda$ mini-batch size
Activate Function
sigmoid:
\[\sigma(z)=\frac1{1+e^{-z}}\]tanh:
\[tanh(z)=\frac{e^z-e^{-z}}{e^z+e^{-z}}\]relu(rectified linear unit):
\[max(0,z)\]Gradient Lost
Gradient will change less in front layers.
CNN
Convolutional Neural Network
RNN
Recurrent Neural Network
LSTM
Long-Short Term Memory Unit
DBN
Deep Belief Network
GAN
Generative Adversarial Networks
Reference
| 微信(WeChat Pay) | 支付宝(AliPay) |

|

|
| 比特币(Bitcoin) | 以太坊(Ethereum) |

|

|
| 以太坊(Base) | 索拉纳(Solana) |

|

|